Estos días he tenido la opción de montar una pequeña prueba de concepto sobre Openstack. La idea es ver como funciona y analizar si en un futuro se podría implementar en un entorno productivo.
Me he basado en la documentación de Cloud – IES Gonzalo Nazareno concretamente en el documento bk-admin-openstack.pdf. También he seguido el libro de «recetas»: OpenStack Cloud Computing Cookbook.
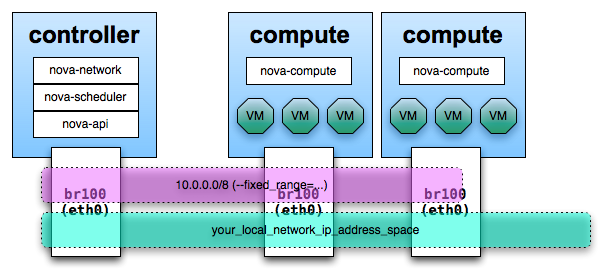
Lo que he montado es básicamente una arquitectura de cuatro nodos. Uno de ellos es el Cloud Controller, donde estará todo el software necesario de Openstack: nova-compute, nova-network, nova-volume, glance y keystone. En los otros tres nodos únicamente se ha instalado el modulo de computación, nova-compute.
El hipervisor elegido para las pruebas ha sido KVM, con la idea de poder tener imagenes de otros sistemas operativos, además de imágenes de distribuciones GNU/Linux.
El esquema lógico sería el siguiente:
Por ciertas limitaciones únicamente he podido disponer de una interfaz de red cableada, por ello he apostado por el diseño mas sencillo con FlatDHCP. Aún así, las instancias son capaces de verse entre si a pesar de correr en diferentes hosts.
Ficheros de configuración:
Tal y como se explica en la documentación, el único fichero que hay que ir tocando es el /etc/nova/nova.conf. Yo copié el que indica en el documento bk-admin-openstack.pdf y lo adapté a mi entorno. Básicamente hay que cambiar la IP que aparece por cada servicio por la del nodo que yo utilizaba como controlador. El apartado que me dió mas problemas fue el de red. Hay que tener mucho cuidado con los segmentos que se definen para las redes privadas, ya que es posible que se den problemas de routing. El apartado de configuración de red quedó de la siguiente manera:
# NETWORK
network_manager=nova.network.manager.FlatDHCPManager
force_dhcp_release=True
dhcpbridge_flagfile=/etc/nova/nova.conf
dhcpbridge=/usr/bin/nova-dhcpbridge
firewall_driver=nova.virt.libvirt.firewall.IptablesFirewallDriver
my_ip=X.X.3.91
public_interface=eth0
flat_network_bridge=br100
flat_interface=eth1
fixed_range=192.168.221.0/27
floating_range=192.168.221.32/27
routing_source_ip=X.X.3.91
start_guests_on_host_boot=true
resume_guests_state_on_host_boot=true
network_size=10
flat_network_dhcp_start=192.168.221.10
flat_injected=False
force_dhcp_release=True
root_helper=sudo nova-rootwrap
El fichero nova.conf será el mismo en todos los nodos, lo único que habrá que cambiar es la variable my_ip. También hay que tener en cuenta la configuración de la consola vnc para poder acceder desde la interfaz web:
# VNC
novnc_enabled=true
vnc_keymap=es
novncproxy_base_url=http://10.150.3.91:6080/vnc_auto.html
vncserver_proxyclient_address=10.150.3.92
vncserver_listen=10.150.3.92
vnc_console_proxy_url=http://10.150.3.91:6080
Aquí habrá que modificar las IPs en las variables vncserver_proxyclient_address y vncserver_listen. En las otras dos variables se dejará la IP del nodo donde se instala la Dashboard.
Como punto importante, ya en la configuración de Keystone, es necesario configurar las variables de entorno del usuario que vamos a autilizar para manejar los servicios de Nova. Para ello, en el fichero .bahsrc hay que introducir las siguientes líneas (en mi caso en el de root):
export SERVICE_ENDPOINT=»http://X.X.3.91:35357/v2.0″
export SERVICE_TOKEN=PASSWORD
export OS_TENANT_NAME=admin
export OS_USERNAME=admin
export OS_PASSWORD=PASSWORD
export OS_AUTH_URL=»http://X.X.3.91:5000/v2.0/»
Una vez con esto configurado ya podemos empezar a hacer pruebas con Openstack.
Problemas encontrados:
Hasta encontrar la configuración que funciona he tenido que ir jugando con los diferentes flags de los ficheros de configuración. Alguna vez, después de arrancar instancias, se han quedado en un estado inconsistente, siendo imposible el borrado de de las instancias de forma convencional. Para ello hay que conectarse a la base de datos y borrar los datos que hacen referencia a las instancias. Para hacerlo mas sencillo me monté un pequeño script en python que saca un listado de las instancias y permite borrar una o el borrado de todas. El script es el siguiente:
#!/usr/bin/python
#coding: iso-8859-15
import MySQLdb
import sys
db = MySQLdb.connect(host=’HOST’,user=’nova’, passwd=’PASSWORD’, db=’nova’)
cursor = db.cursor()
consulta = ‘select id, uuid from instances’
cursor.execute(consulta)
instances = cursor.fetchall()
for inst in instances:
print «Instancia: %s UUID: %s» % (str(inst[0]), str(inst[1]))
if «–all» in sys.argv:
print ‘Limpiando todas las instancias’
cont = raw_input(‘¿Continuar? (s/n): ‘)
if cont == ‘s’ or cont == ‘S’:
for inst in instances:
id=str(inst[0])
print ‘Borrando instancia %s’ % id
consulta = ‘delete from instance_info_caches where id=%s’ % id
cursor.execute(consulta)
consulta = ‘delete from security_group_instance_association where id=%s’ % id
cursor.execute(consulta)
consulta = ‘delete from instances where id=%s’ % id
cursor.execute(consulta)
db.commit()
print ‘Todas las instancias borradas’
else:
id = raw_input(‘Selecciona la instancia a borrar: ‘)
for inst in instances:
if str(inst[0]) == id:
print «Se va a borrar la instancia %s con UUID %s» % (str(id), str(inst[1]))
cont = raw_input(‘¿Continuar? (s/n): ‘)
if cont == ‘s’ or cont == ‘S’:
print ‘Borrando instancia %s’ % id
consulta = ‘delete from instance_info_caches where id=%s’ % id
cursor.execute(consulta)
consulta = ‘delete from security_group_instance_association where id=%s’ % id
cursor.execute(consulta)
consulta = ‘delete from instances where id=%s’ % id
cursor.execute(consulta)
print ‘Ejecute «nova list | grep %s» para confirmar que se ha borrado la instancia’ % str(inst[1])
db.commit()
En una ocasión no pude borrar la instancia con el script y era porque a la instancia le había asignado un volumen. Al borrar daba un error de clave referenciada en una tabla, con lo que tuve que borrar dicha entrada en la tabla que indicaba el error. Una vez limpiado se pudo borrar con el script.
Es importante, en caso de tener algún problema, revisar los logs. Allí encontraremos muchas pistas de que puede estar fallando y es muy probable que a alguien le haya pasado antes. Los logs de nova se encuentran en /var/logs/nova y los de KVM, no menos importantes, están en /var/logs/libvirt.